 +23.6 °C
+23.6 °C
 Знакомства Женщина (65 -162-63) желает познакомиться с одиноким, добродушным, без вредных ...
Знакомства Познакомлюсь с мужчиной любящим танцевать и петь на родном чувашском языке
Знакомства Хочу познакомиться с женщиной до 55 лет чувашской или русской национальности дл...
Знакомства Женщина (65 -162-63) желает познакомиться с одиноким, добродушным, без вредных ...
Знакомства Познакомлюсь с мужчиной любящим танцевать и петь на родном чувашском языке
Знакомства Хочу познакомиться с женщиной до 55 лет чувашской или русской национальности дл...
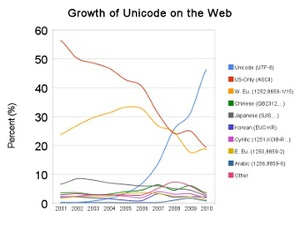
Доля кодировки Unicode в интернет-документах приблизилась к 50 процентам. Об этом говорится в записи в блоге Google. Для расчетов компания, давно перешедшая на Unicode, использовала данные собственного поискового индекса.
Unicode впервые обогнал все другие кодировки в мае 2008 года. Тогда его доля составляла около 25 процентов, как и доли ASCII- и западноевропейской кодировок. В 2001 году доля ASCII-кодировки составляла около 55 процентов. Сейчас она снизилась до 20.
Доли других популярных национальных кодировок, в том числе и распространенной в России CP-1251 не превышают десяти, а чаще и пяти процентов.
Многобайтовый стандарт кодирования символов Unicode позволяет использовать символы тысяч национальных алфавитов и представить знаки практически всех письменных языков, в то время как обычные кодировки ограничиваются поддержкой максимум нескольких десятков языков и нескольких алфавитов.
Еще больше интересных и актуальных новостей вы найдете в чувашской версии сайта!
